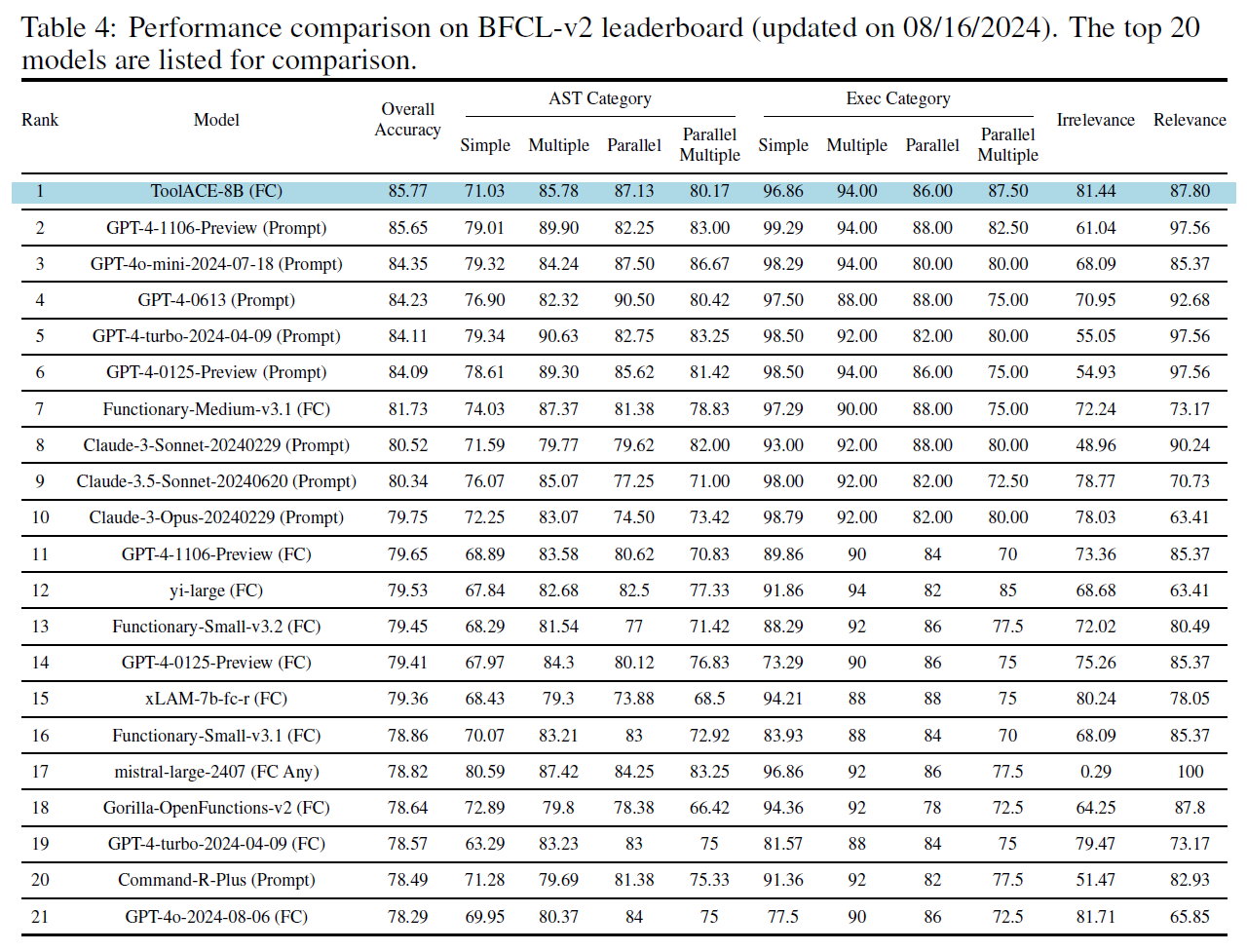
近日,计算机科学与技术学院、认知智能全国重点实验室陈恩红教授团队联合华为等单位发布了新的工具调用模型ToolACE,在开源工具调用榜单BFCL(美国伯克利大学发布的函数调用榜单)中效果持平千亿参数量级别模型GPT4,获得开源模型的第一名。
大语言模型(如GPT-4)具备强大的语言处理能力,但其独立运作时仍存在局限性,比如,无法进行复杂数学计算、获取不到实时信息、难以提供专业定制化功能等。而通过为大语言模型提供各类工具,可以使其提供更全面、实时、精确的服务,极大地扩展了其应用范围和实际价值。
高质量、多样化且复杂的训练数据在提升模型的工具调用能力方面起着至关重要的作用。然而,在现实中,工具调用数据的收集和标注极为困难,现有的合成数据生成方式在覆盖率和准确性方面仍存在不足。研究人员从训练数据生成的角度提出了新的工具调用数据合成框架,其通过创新的自进化合成过程,构建了一个应用程序接口库,其中涵盖了26507个多样化的应用程序接口(API)。通过多智能体之间的交互生成对话,并利用形式化的思维链过程引导数据生成,得到一系列真实、多样、复杂的对话数据。进一步结合了基于规则和基于模型的数据质检机制,验证数据中工具使用和参数的合理性,确保了数据的准确性。研究人员最后基于合成的高质量数据训练出了工具调用模型ToolACE,以80亿的模型参数量级拥有和千亿参数量级别大语言模型GPT4持平的工具调用能力,在工具调用榜单BFCL(伯克利函数调用榜单)中获得开源模型第一,超过如Functionary等700亿模型效果。
该研究受到国家自然科学基金项目、中国科大-华为人工智能创新实验室项目的支持。
